Organization Theory for the AI Era
AI-native companies are not simply companies that use AI tools. They are organizations that treat agents as team members, which changes hiring, onboarding, permissioning, trust, evaluation, and management.
Most companies that say they are becoming AI-native are still describing the change in tool language.
They ask: which AI tools should we buy? Which workflows can we automate? How much productivity can a model add to an existing team?
Those are reasonable questions, but I think they miss the deeper shift.
An AI-native company is not simply a company that uses AI tools. It is a company that treats agents as members of the organization.
That sounds like a small distinction, but it changes almost everything. If AI is a tool, the main question is efficiency: how much faster can this make an existing person? If an agent is a team member, the questions become organizational:
- What role should it own?
- What context does it need?
- What permissions should it receive?
- Who is responsible for its output?
- How do we evaluate it?
- When should we trust it more?
- When should we reduce its scope, retrain it, replace it, or retire it?
This is not only a technical problem. It is an organizational design problem.
The next useful frame may not be “how to use AI at work.” It may be something closer to organization theory for the AI era.
From Tool To Team Member
The easiest way to see the difference is to compare two questions.
If AI is a tool, you ask:
What can this tool help me do?
If an agent is a team member, you ask:
What responsibility can this member reliably carry inside this organization?
The second question is much harder.
When a human employee joins a company, the organization does not only give them a task. It gives them a role, an identity, access, context, norms, history, feedback, and a path for trust to change over time.
We do not expect a new employee to perform well with a single prompt. We onboard them. We explain the company, the customer, the current goals, the things that have already been tried, the boundaries they should not cross, and the judgment standards of the team.
Then we watch how they work.
If they perform well, we give them more responsibility. If they make mistakes, we narrow the scope, give feedback, change the manager, change the role, or eventually let them go.
If agents are going to do real work, they need a version of this lifecycle too.
Not because they are people. They are not.
But because the organization is asking them to occupy a role inside a system of responsibility.
That means the interesting unit is no longer the prompt. The interesting unit is the agent lifecycle:
- recruiting
- onboarding
- permissioning
- context management
- memory management
- evaluation
- feedback
- promotion
- retirement
This is why the AI-native company is not just an automation story. It is a new organizational form.
Organization Theory For The AI Era
Traditional organization theory assumes that the members of an organization are humans.
The org chart reflects this assumption. It shows CEOs, VPs, managers, individual contributors, departments, and reporting lines. It answers questions like: Who reports to whom? Who owns which function? Where does authority sit?
That chart will still matter.
But it will not be enough.
In an AI-native organization, the working members of the system may include:
- humans
- individual agents
- human-agent pairs
- agent teams
- manager agents
- specialized workflow agents
- autonomous departments
- AI-assisted organizations
Once this happens, the real operating structure of a company is no longer fully captured by a reporting line.
It needs another graph.
I think of it as an Intelligence Graph.
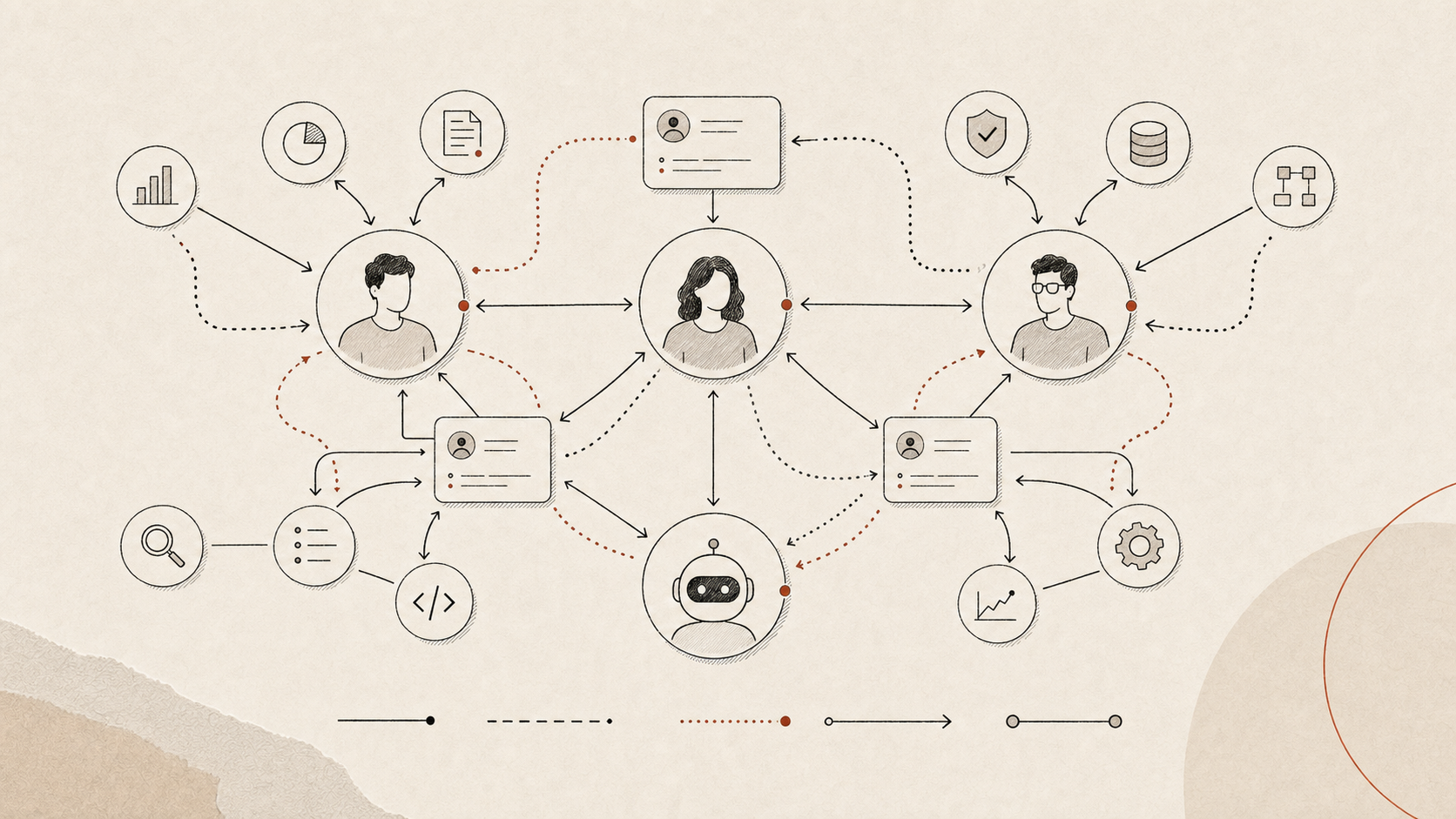
The Intelligence Graph does not primarily show titles. It shows working relationships between intelligences:
- Who trusts whom?
- Who gives context to whom?
- Who grants permission?
- Who evaluates the work?
- Who can call which agent?
- Who can modify which system?
- Who is responsible for which outcome?
- Which memories and artifacts flow through the system?
This graph may become more operationally important than the traditional org chart.
The org chart tells you formal authority. The Intelligence Graph tells you how work actually moves.
What It Means To Hire An Agent
If an agent can be a team member, then “hiring an agent” needs a more precise meaning.
Hiring a human means bringing a capable person from the labor market into the organization. Hiring software means buying a tool.
Hiring an agent is something between those two, but not identical to either.
It means finding, evaluating, and connecting an intelligence that can carry a responsibility inside a specific organizational context.
That agent can come from several places.
One source is a vendor agent. This is closest to how companies buy software today. A company might adopt a research agent, a coding agent, a compliance agent, or a data agent from an external provider. On the surface this looks like procurement. In practice, the company is importing a trained digital worker and deciding what responsibility it can safely hold.
Another source is a marketplace agent. A future agent marketplace will not be just a prompt marketplace or plugin store. The more interesting version is closer to a labor market for roles. You do not select “a model.” You select a senior financial analyst agent, a legal reviewer agent, a QA agent, a product manager agent, or a security auditor agent. The object being chosen is not just capability. It is a role-shaped package of capability, context requirements, permission boundaries, and evaluation criteria.
A third source is the organization-trained agent. This may become the most valuable category. It starts as a general system, but over time it becomes shaped by the company’s customers, codebase, decisions, preferences, failures, and rituals. Its value is not only model intelligence. Its value is organizational memory.
This is the part many people underweight. A company memory system is not just a better knowledge base. It is the substrate that allows agents to become long-running members of the organization instead of disposable chat sessions.
A fourth source is the spawned agent. This is the most AI-native pattern. The organization does not go to the market for every new role. It creates new agents when the work demands it. A manager agent might spawn a documentation agent, a migration agent, a QA agent, or a customer research agent for a bounded mission.
This is a little like autoscaling, except the scaling target is not compute.
It is organizational capacity.
The Missing Trust Layer
Once agents become team members, the next problem appears immediately:
Why should I trust this agent?
In human organizations, we already have imperfect but familiar trust infrastructure. Resumes, references, portfolios, GitHub histories, performance reviews, interview loops, credentials, reputations, and trial projects all exist to answer some version of: should this person be trusted with this work?
Agent work has much less of this infrastructure.
We have model benchmarks, but model benchmarks are only the shallowest layer. They answer whether a model performs well on a test. They do not answer whether a specific agent, inside a specific organization, with specific tools and context, can produce reliable work over time.
The future needs a trust layer for intelligence.
At the first level, we can evaluate the agent itself: success rate, failure rate, cost, speed, accuracy, hallucination rate, tool use, context handling, and long-task reliability.
At the second level, we can evaluate real work. A coding agent, for example, should not only be judged by a benchmark. It should be judged by accepted pull requests, bug introduction rate, test pass rate, unnecessary code churn, review comments, style consistency, and whether it respects the boundaries of a large repo.
At the third level, we can evaluate the human. This may feel strange, but it is unavoidable. Some people are much better at managing agents than others. They express goals clearly. They provide context. They decompose work. They set evals. They give useful feedback. They know when to grant permission and when to keep a system read-only.
This becomes a new management skill: AI-native management.
At the fourth level, we evaluate the collaboration. The most useful question is often not “which agent is best?” It is “which human-agent pair produces the best result in this environment?”
A brilliant agent with a vague manager may perform poorly. A merely good agent with a strong operator may perform extremely well. The pair matters.
At the fifth level, we evaluate the organization. Does the company reuse context well? Does memory improve over time? Are trust boundaries clear? Are agents evaluated against outcomes? Are humans still the bottleneck for everything? Can the organization delegate safely without losing accountability?
The more agentic a company becomes, the more its advantage depends on the quality of this trust infrastructure.
The Primitives Of An AI-Native Organization
Before this can be managed well, we need better primitives.
By primitive, I do not mean something crude or simplistic. I mean a basic concept that complex systems are built from.
Operating systems have primitives like files, processes, threads, and permissions. Companies have primitives like roles, teams, budgets, managers, goals, and reviews.
AI-native organizations need their own primitives.
The first is role. What is this intelligence responsible for? Research assistant, backend engineer, QA agent, data analyst, manager agent, chief of staff agent. Role defines the boundary of responsibility.
The second is identity. Does this agent persist? Does it have a name, history, reputation, and owner? A disposable chat session behaves like a tool. A long-running agent with memory and responsibility behaves more like a member.
The third is goal. Why does it exist? Agents should not be created to chat. They should exist to move a class of organizational outcomes.
The fourth is context. What does it need to know? Company background, project goals, repo structure, customer constraints, past decisions, team norms, business rules, and current priorities.
The fifth is memory. What should it keep over time? Which decisions failed? Which modules are fragile? Which customers are unusual? Which preferences should not be rediscovered every week?
The sixth is permission. What can it do? Read code? Write code? Open pull requests? Merge? Access customer data? Send email? Modify production? Create other agents?
The seventh is trust. What responsibility is the organization actually willing to give it? Permission is a system boundary. Trust is an organizational judgment. The two should be related, but they are not identical.
The eighth is evaluation. How do we know whether it is doing good work? Tests, review, user satisfaction, cost, latency, failure categories, peer-agent review, and long-term outcomes all matter.
The ninth is feedback. Who teaches it? A human manager, a tech lead, a user, a test suite, production metrics, another agent, or an evaluation system?
The tenth is evolution. How does it grow? Can it receive more context, handle harder work, manage a module, coordinate other agents, or be copied into another team?
The eleventh is lifecycle. How is it recruited, onboarded, used, evaluated, promoted, replaced, and retired?
These primitives sound abstract, but they are practical. Without them, companies will keep treating agents as magic tools and then be surprised when they cannot manage reliability, trust, or accountability.
A Concrete Example
Imagine a company wants a backend engineer agent.
The weak version of the request is:
We need an agent that can help write backend code.
That is too vague. It describes a capability, not an organizational member.
A better version would define the agent through primitives.
Its role is senior backend engineer agent. Its identity is persistent and owned by an engineering manager. Its goal is to support backend development, code review, test repair, technical debt reduction, and small architecture improvements.
Its required capabilities might include API design, database schema changes, tests, observability, refactoring, large-repo navigation, and technical documentation.
Its onboarding context would include the product overview, backend architecture, repo structure, API conventions, coding style, test commands, CI flow, historical architecture decisions, current sprint goals, and forbidden areas.
Its memory would track modules it has touched, bugs it has fixed, tests that are flaky, design decisions that have already been rejected, and team preferences it should preserve.
Its initial permission boundary might be narrow. It can read the repo, create branches, and open pull requests. It cannot merge. It cannot access production data. It cannot modify billing, authentication, or security-sensitive code without explicit authorization. It cannot send customer emails.
Its trust level can then change over time. At first it may only generate suggestions. Later it may modify non-critical code. Then it may independently handle low-risk tasks. Eventually it may maintain a module or coordinate other agents.
Its evaluation should be specific: pull request acceptance rate, bug introduction rate, test pass rate, review comments, completion time, context misuse incidents, security boundary violations, and unnecessary code change rate.
Its feedback loop comes from the tech lead, CI results, code review comments, QA agents, production monitoring, and periodic performance summaries.
If it performs well, the organization can expand its scope. If it performs poorly, the organization can narrow permissions, reduce task complexity, re-onboard it, change the underlying harness, or retire it.
That is a very different object from a prompt.
It is an intelligence being connected to an organization.
The Smallest Useful Experiment
The right first experiment is probably not to build a full agent marketplace or a complete evaluation platform.
It is much smaller:
Hire your first agent.
Not as a slogan. As a concrete workflow.
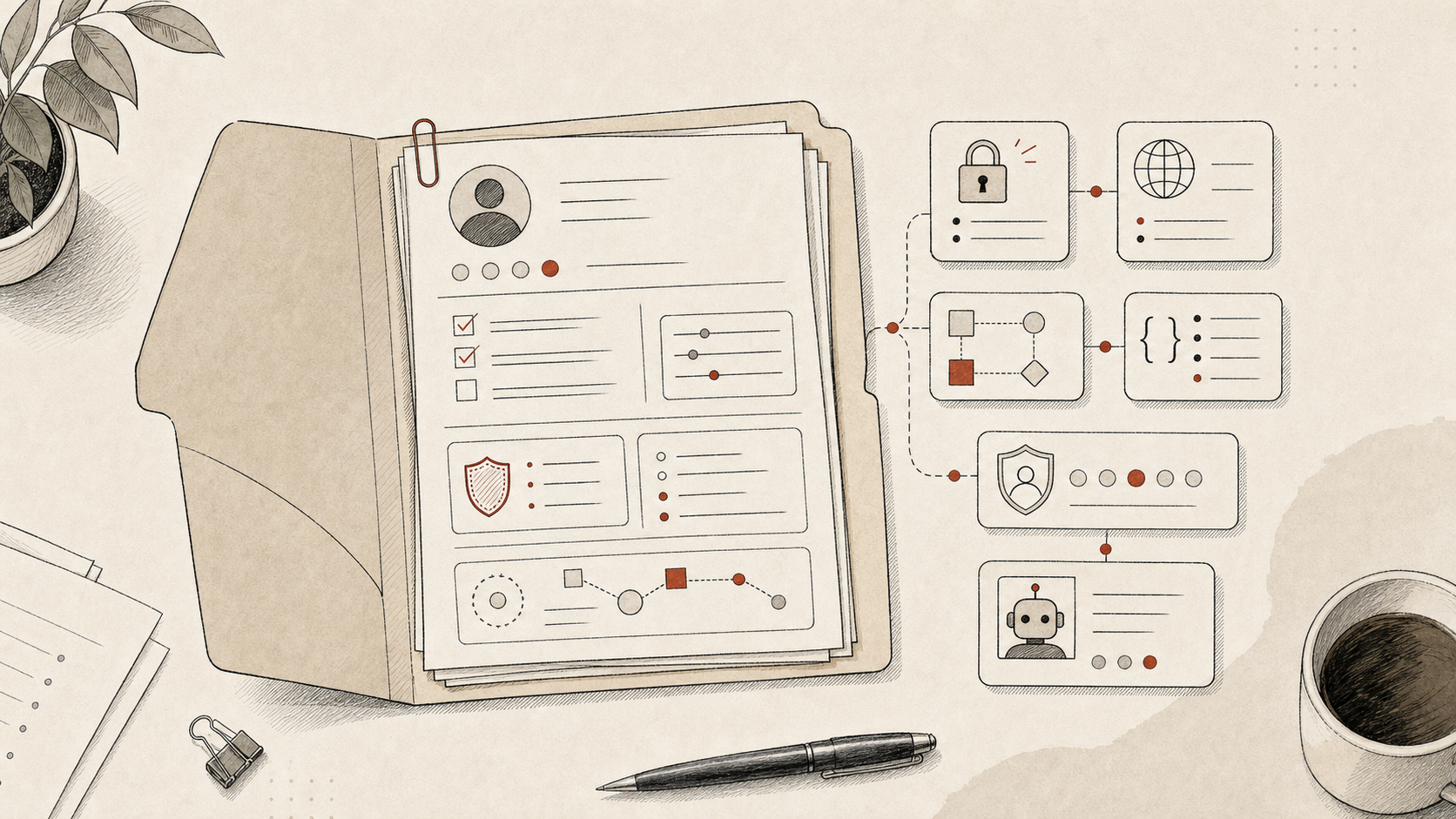
A simple version could be a document or webpage that does not start by asking:
Which model do you want?
It starts by asking:
What role do you need?
The output is not a prompt. The output is an Agent Hiring Packet:
- role description
- required capabilities
- required context
- permission boundary
- trust levels
- onboarding plan
- first seven days of tasks
- evaluation metrics
- feedback loop
- promotion and retirement criteria
This is useful even before the agent is fully automated.
Because it forces the organization to answer the real question:
What does it mean to bring an intelligence into the company and let it carry responsibility?
That question is the beginning of AI-native organization design.
The Real Shift
The important shift is not that software gets smarter.
It is that the basic member of the organization changes.
Once agents become team members, the company has to redesign the surrounding system: hiring, onboarding, permissioning, context, memory, trust, evaluation, feedback, promotion, and retirement.
The companies that do this well will not simply have more automation. They will have a different operating model. They will know how to combine humans and agents into reliable systems of work.
This is why I think “AI-native” is not mainly a tooling category.
It is an organizational category.
The question is not: how much AI does this company use?
The better question is:
Has this company learned how to manage intelligence?
That may become one of the central management questions of the next decade.
Related writing
Every Developer Should Be The Tech Lead
In the age of agents, the scarce developer skill is no longer just writing code. It is defining intent, decomposing work, directing agents, reviewing outputs, and owning the final technical judgment.
Code Is Cheap. Taste, Intent, and Eval Are Not.
The scarce skill for AI-native developers is no longer just writing code. It is knowing what good looks like, expressing intent clearly, and building mechanisms that can tell whether the result actually works.
Analytics AI Has an Access Problem. The Real Problem Is Judgment.
Most analytics AI tools are built to give models better access to data. The actual gap is upstream of access — whether the system knows when it doesn't know enough, and what to do about that.