AI 时代的组织学
AI Native 公司不是简单使用 AI 工具的公司,而是把 Agent 当作组织成员来设计、授权、评估和管理的公司。
今天很多公司说自己正在变成 AI Native,但大多数时候,它们仍然在用“工具”的语言描述这件事。
它们会问:我们应该买哪些 AI 工具?哪些流程可以自动化?一个模型能让现有团队提高多少效率?
这些问题都合理。但我觉得它们没有触到更深的变化。
AI Native 公司不是简单使用 AI 工具的公司。它是把 Agent 当作组织成员来设计的公司。
这听起来只是一个小小的措辞差异,但它几乎会改变所有问题。如果 AI 是工具,我们关心的是效率:它能让某个人变快多少?如果 Agent 是 Team Member,我们关心的就变成组织问题:
- 它应该负责什么角色?
- 它需要什么 context?
- 它应该获得什么 permission?
- 谁对它的输出负责?
- 我们如何评价它?
- 什么时候应该更信任它?
- 什么时候应该缩小它的范围、重新训练它、替换它,或者让它退休?
这不只是一个技术问题。
它是一个组织设计问题。
下一套真正有用的框架,可能不是“如何在工作中使用 AI”。它更接近于:AI 时代的组织学。
从工具到成员
最简单的区别,是比较两个问题。
如果 AI 是工具,你会问:
这个工具能帮我做什么?
如果 Agent 是 Team Member,你会问:
这个成员能在这个组织里可靠承担什么责任?
第二个问题要难得多。
当一个人类员工加入公司时,公司不会只是给他一个任务。公司会给他角色、身份、权限、上下文、团队规范、历史信息、反馈机制,以及一条信任逐渐变化的路径。
我们不会期待一个新员工靠一个 prompt 就表现很好。我们会 onboard 他。我们会解释公司、客户、当前目标、已经试过什么、哪些边界不能碰,以及团队判断好坏的标准。
然后我们观察他如何工作。
如果表现稳定,我们给他更多责任。如果出错,我们缩小范围、给反馈、换 manager、换角色,或者最终让他离开。
如果 Agent 要做真实工作,它也需要某种版本的 lifecycle。
不是因为 Agent 是人。它不是。
而是因为组织正在让它占据一个有责任边界的角色。
所以真正有意思的单位,不再是 prompt。
真正有意思的单位,是 Agent Lifecycle:
- recruiting
- onboarding
- permissioning
- context management
- memory management
- evaluation
- feedback
- promotion
- retirement
这就是为什么 AI Native 公司不只是一个自动化故事。它是一种新的组织形态。
AI 时代的组织学
传统组织学默认组织成员是人。
Org chart 反映的就是这个默认假设。它展示 CEO、VP、manager、individual contributor、department 和 reporting line。它回答的问题是:谁向谁汇报?谁负责哪个职能?权力坐在哪里?
这张图仍然重要。
但它不够了。
在 AI Native 组织里,真实参与工作的成员可能包括:
- human
- individual agent
- human-agent pair
- agent team
- manager agent
- specialized workflow agent
- autonomous department
- AI-assisted organization
一旦这些成员出现,公司真实的运转结构就不再能被 reporting line 完整表达。
它需要另一张图。
我会把它叫做 Intelligence Graph。
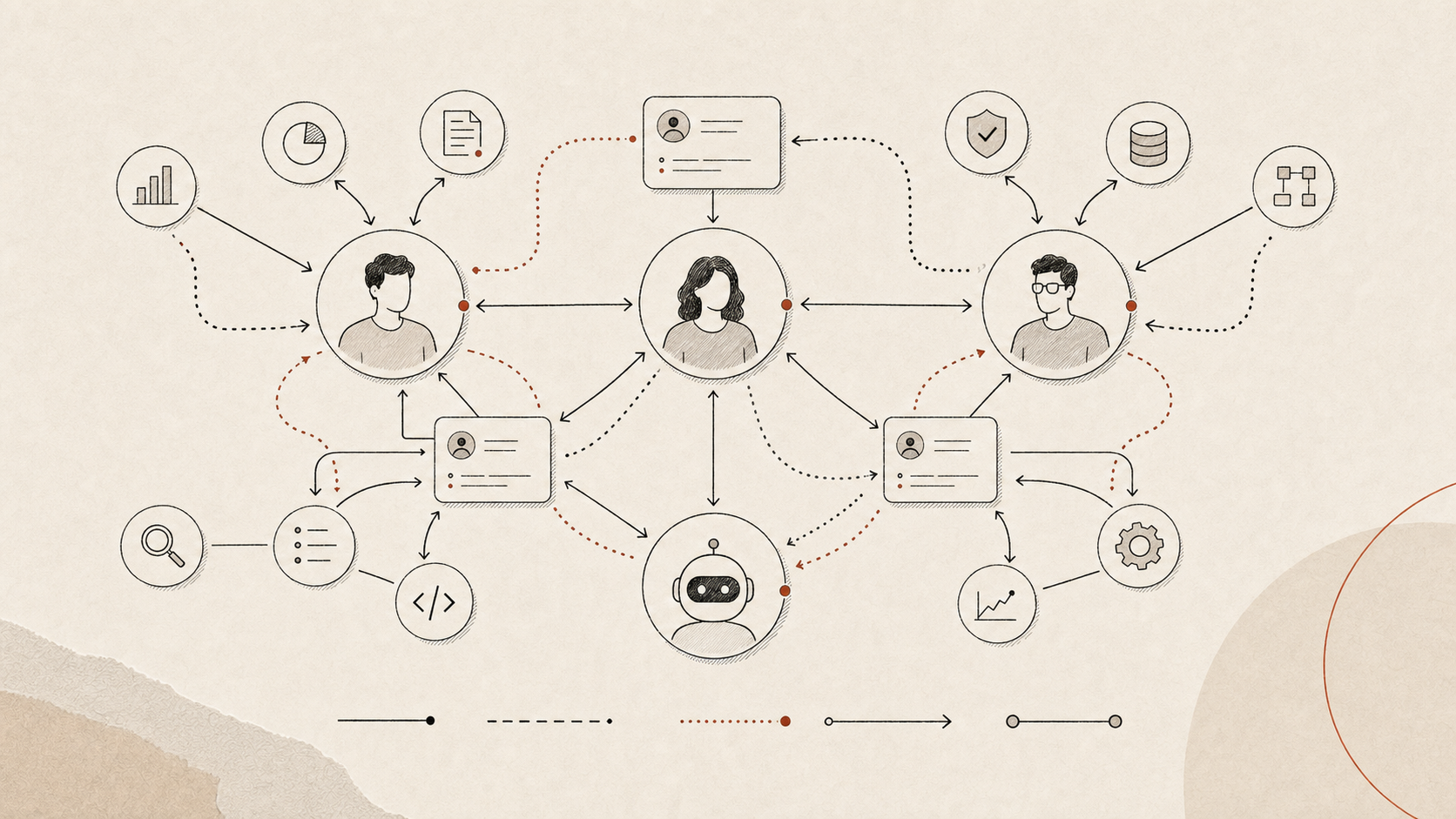
Intelligence Graph 主要展示的不是 title,而是 intelligence 之间的工作关系:
- 谁信任谁?
- 谁向谁提供 context?
- 谁授予 permission?
- 谁评价谁的工作?
- 谁可以调用哪个 agent?
- 谁可以修改哪个系统?
- 谁对哪个结果负责?
- 哪些 memory 和 artifact 在系统里流动?
这张图可能会比传统 org chart 更接近公司的真实操作结构。
Org chart 告诉你正式权力在哪里。Intelligence Graph 告诉你工作实际上如何流动。
招聘一个 Agent 意味着什么
如果 Agent 可以是 Team Member,那么“招聘一个 Agent”也需要更精确的定义。
招聘一个人,意味着从劳动力市场把一个有能力的人带入组织。购买软件,意味着获得一个工具。
招聘 Agent 介于两者之间,但又不完全等同于任何一个。
它的意思是:寻找、评估并接入一个 intelligence,让它能在特定组织上下文里承担某种责任。
Agent 可能来自几种地方。
第一种是 vendor agent。这最接近今天公司购买软件的方式。一家公司可能采用外部提供的 research agent、coding agent、compliance agent 或 data agent。表面上看,这是采购。实际上,公司是在引入一个训练好的数字工作者,并决定它能安全承担什么责任。
第二种是 marketplace agent。未来的 agent marketplace 不应该只是 prompt marketplace 或 plugin store。更有意思的版本,会更像一个面向角色的劳动力市场。你选择的不是“一个模型”,而是 senior financial analyst agent、legal reviewer agent、QA agent、product manager agent 或 security auditor agent。被选择的不是单点能力,而是一套被角色封装起来的东西:能力、上下文要求、权限边界和评估标准。
第三种是 organization-trained agent。这可能会成为最有价值的一类。它一开始也许只是一个通用系统,但随着时间推移,它会被公司的客户、代码库、历史决策、偏好、失败经验和团队 ritual 塑形。它的价值不只来自模型智能,也来自组织记忆。
这一点经常被低估。
公司记忆系统不只是更好的知识库。它是让 Agent 从一次性 chat session 变成长周期组织成员的底层土壤。
第四种是 spawned agent。这是更 AI Native 的模式。组织不需要为每一个新角色都去市场寻找。它可以在工作需要时生成新的 agent。一个 manager agent 可能为了一个边界清晰的任务,创建 documentation agent、migration agent、QA agent 或 customer research agent。
这有点像 autoscaling。
只是被扩容的对象不是计算资源。
而是组织能力。
缺失的 Trust Layer
一旦 Agent 成为 Team Member,下一个问题会立刻出现:
我为什么应该信任这个 Agent?
在人类组织里,我们已经有一套不完美但熟悉的信任基础设施。Resume、reference、portfolio、GitHub history、performance review、interview loop、credential、reputation 和 trial project,都是在回答某种版本的问题:这个人是否值得被信任去做这件事?
Agent 的工作还缺少这样的基础设施。
我们有 model benchmark,但 model benchmark 只是最浅的一层。它回答的是某个模型在某个测试上表现如何。它不能回答一个具体 agent,在一个具体组织里,带着具体工具和 context,能不能长期稳定地产生可靠工作。
未来需要一个 intelligence 的 trust layer。
第一层,是评价 agent 本身:成功率、失败率、成本、速度、准确性、幻觉率、工具调用、context 使用、长任务可靠性。
第二层,是评价真实工作。一个 coding agent 不应该只被 benchmark 衡量。它应该被已接受的 PR、引入 bug 的比例、测试通过率、不必要的代码 churn、review 反馈、风格一致性,以及是否尊重大型 repo 边界来衡量。
第三层,是评价人。这听起来有点奇怪,但它不可避免。有些人明显更擅长管理 agent。他们能清楚表达目标,提供 context,拆解工作,设计 eval,给出有用反馈,也知道什么时候应该授权,什么时候必须保持 read-only。
这会成为一种新的管理能力:AI Native Management。
第四层,是评价 collaboration。最有价值的问题往往不是“哪个 agent 最好”,而是“哪个 human-agent pair 在这个环境里产出最好”。
一个很强的 agent,遇到目标模糊的 manager,可能表现很差。一个只是不错的 agent,遇到很强的 operator,可能表现极好。组合很重要。
第五层,是评价组织。公司是否能复用 context?Memory 是否会随时间变好?Trust boundary 是否清楚?Agent 是否根据结果被评价?Human 是否仍然是所有事情的瓶颈?组织能否安全地委托工作,同时不丢掉 accountability?
公司越依赖 Agent 运转,它的优势就越依赖这层 trust infrastructure 的质量。
AI Native 组织的 Primitive
在真正管理这件事之前,我们需要更好的 primitive。
这里的 primitive 不是“原始”或“粗糙”的意思。它指的是复杂系统建立在其上的基础概念。
操作系统有 file、process、thread、permission 这样的 primitive。公司有 role、team、budget、manager、goal、review 这样的 primitive。
AI Native 组织也需要自己的 primitive。
第一个是 role。这个 intelligence 负责什么?Research assistant、backend engineer、QA agent、data analyst、manager agent、chief of staff agent。Role 定义责任边界。
第二个是 identity。这个 agent 是否持续存在?它是否有名字、历史、声誉和 owner?一次性 chat session 更像工具。一个拥有 memory 和责任的 long-running agent 更像成员。
第三个是 goal。它为什么存在?Agent 不应该为了聊天而被创建。它应该为了推动某类组织结果而存在。
第四个是 context。它需要知道什么?公司背景、项目目标、repo 结构、客户约束、历史决策、团队规范、业务规则和当前优先级。
第五个是 memory。它应该长期保留什么?哪些决策失败过?哪些模块很脆弱?哪些客户很特殊?哪些偏好不应该每周重新发现一次?
第六个是 permission。它能做什么?读代码?写代码?开 PR?Merge?访问客户数据?发邮件?修改生产环境?创建其他 agent?
第七个是 trust。组织实际上愿意把什么责任交给它?Permission 是系统边界。Trust 是组织判断。两者应该相关,但并不完全相同。
第八个是 evaluation。我们如何知道它做得好?测试、review、用户满意度、成本、延迟、失败类型、peer-agent review 和长期结果,都重要。
第九个是 feedback。谁教它?Human manager、tech lead、user、test suite、production metrics、另一个 agent,或者一个评估系统?
第十个是 evolution。它如何成长?它能否获得更多 context,处理更难的工作,维护某个模块,协调其他 agent,或者被复制到另一个团队?
第十一个是 lifecycle。它如何被招聘、入职、使用、评估、晋升、替换和退休?
这些 primitive 听起来抽象,但其实很实际。没有它们,公司会继续把 agent 当成魔法工具,然后惊讶地发现自己无法管理 reliability、trust 和 accountability。
一个具体例子
假设一家公司想要一个 backend engineer agent。
弱版本的请求是:
我们需要一个能帮忙写后端代码的 Agent。
这太模糊了。它描述的是 capability,不是一个组织成员。
更好的版本,会用 primitive 来定义这个 agent。
它的 role 是 senior backend engineer agent。它的 identity 是持续存在的,并由 engineering manager 负责。它的 goal 是支持后端开发、代码 review、测试修复、技术债整理和小型架构改进。
它需要的 capability 可能包括 API design、database schema change、testing、observability、refactoring、大型 repo navigation 和 technical documentation。
它的 onboarding context 应该包括产品概览、后端架构、repo 结构、API 约定、coding style、测试命令、CI 流程、历史架构决策、当前 sprint 目标和禁止修改区域。
它的 memory 应该记录:它碰过哪些模块,修过哪些 bug,哪些测试 flaky,哪些设计方案已经被否定,哪些团队偏好必须保留。
它的初始 permission boundary 应该比较窄。它可以读 repo、创建 branch、打开 PR。它不能 merge。不能访问 production data。不能在没有明确授权的情况下修改 billing、auth 或 security-sensitive code。不能直接给客户发邮件。
然后它的 trust level 可以随着表现变化。最开始,它也许只能生成建议。之后,它可以修改非关键代码。再之后,它可以独立处理低风险任务。最终,它可能维护一个模块,甚至协调其他 agent。
它的 evaluation 应该具体:PR acceptance rate、bug introduction rate、test pass rate、review feedback、completion time、context misuse incidents、security boundary violations 和 unnecessary code change rate。
它的 feedback loop 来自 tech lead、CI results、code review feedback、QA agents、production monitoring 和周期性 performance summary。
如果表现好,组织可以扩大它的 scope。如果表现不好,组织可以缩小 permission、降低任务复杂度、重新 onboarding、更换底层 harness,或者 retire 它。
这和 prompt 完全不是一个东西。
这是把一个 intelligence 接入组织。
最小可用实验
最合适的第一个实验,可能不是搭一个完整的 agent marketplace,也不是做一个完整的 evaluation platform。
它应该更小:
Hire your first agent.
这不是一句 slogan,而是一个具体 workflow。
一个简单版本,可以是一个文档或网页。它一开始不问:
Which model do you want?
它先问:
What role do you need?
它输出的也不是 prompt,而是一份 Agent Hiring Packet:
- role description
- required capabilities
- required context
- permission boundary
- trust levels
- onboarding plan
- first seven days of tasks
- evaluation metrics
- feedback loop
- promotion and retirement criteria
即使这个 agent 还没有完全自动化,这件事也有价值。
因为它迫使组织回答真正的问题:
把一个 intelligence 带进公司,并让它承担责任,到底意味着什么?
这个问题,就是 AI Native organization design 的起点。
真正的变化
真正重要的变化,不是软件变聪明了。
而是组织的基本成员变了。
一旦 Agent 成为 Team Member,公司就必须重新设计它周围的系统:招聘、入职、权限、context、memory、trust、evaluation、feedback、晋升和退休。
做得好的公司,不只是拥有更多自动化。它们会拥有一种不同的 operating model。它们知道如何把 human 和 agent 组合成可靠的工作系统。
所以我认为,AI Native 主要不是一个工具范畴。
它是一个组织范畴。
问题不是:
这家公司用了多少 AI?
更好的问题是:
这家公司是否学会了管理 intelligence?
这可能会成为未来十年最重要的管理问题之一。
相关阅读
每个开发者都应该成为 Tech Lead
在 agent 时代,developer 的稀缺能力不只是亲手写代码,而是定义目标、拆解工作、指挥 agent、审查结果,并对最终技术判断负责。
代码正在变便宜,Taste、Intent 和 Eval 变贵了
AI-native developer 的稀缺能力,不只是写代码,而是知道什么是好,能把意图表达清楚,并建立机制判断结果是否真的达标。
Analytics AI 的问题不是访问数据,而是判断力
大多数 analytics AI 工具都在努力让模型获得更多数据上下文。但真正的缺口更靠前:系统是否知道自己什么时候还不够确定,以及接下来该做什么。